前回は Python の開発環境について書きました。
Anacondaで始めるPython生活!
今回は実際に Python でコーディングしていこうと思います。
足し算とか引き算とかやっても面白くないですよね。
そこで今回は「 DMM 2018年度における Top100 のAVのタイトルを分析」をしようと思います。
今回のコード
!pip install janome
!pip install wordcloud
from selenium import webdriver
import pandas as pdbrowser = webdriver.Chrome(executable_path='chromedriver が格納されているパス')
url = "http://www.dmm.co.jp/digital/videoa/-/ranking/=/year="
#実行部分
for q in range(2010, 2019):
df = []
df = pd.DataFrame(columns=["rank", "title"])
for x in range(1, 6):
#ページ取得
browser.get(url + str(q) + "/page=" + str(x))
print(url+ str(q) + "/page=" + str(x))
#データ取得
posts = browser.find_elements_by_class_name("bd-b")
print("Starting to get posts...")
print(len(posts))
for post in posts:
try:
rank = post.find_element_by_css_selector(".rank").text
print("ランク:{}".format(rank))
title = post.find_element_by_css_selector('img').get_attribute('alt')
print("タイトル:{}".format(title))
se = pd.Series([rank, title],["rank", "title"])
df = df.append(se, ignore_index=True)
except Exception as e:
print(e)
print("Finished Scraping. Writing CSV.......")
df.to_csv("dmm_ranking" + str(q) + ".csv")
print("DONE")from janome.tokenizer import Tokenizer
import matplotlib.pyplot as plt
from wordcloud import WordCloud
import pandas as pd
train = pd.read_csv("dmm_ranking2018.csv")
title_texts = train["title"].values.tolist()
words = []
t = Tokenizer()
for title_text in title_texts:
tokens = t.tokenize(title_text)
for token in tokens:
# 品詞を取り出し
partOfSpeech = token.part_of_speech.split(',')[0]
if partOfSpeech == '名詞':
words.append(token.base_form)
text = ' '.join(words)
#word cloud
fpath = r"C:\\Windows\\Fonts\\Kosugi-Regular.ttf"
wordcloud = WordCloud(background_color="white", font_path=fpath,width=900, height=500).generate(text)
plt.figure(figsize=(10,8))
plt.imshow(wordcloud)
plt.axis("off")
plt.show()分析結果の確認
2つ目のコードの実行が終わると画像のように出力されます。
「はい、そうですか」という感じです。
今回の本題は3つ目の結果の方です。
タイトルが卑猥なので一部伏せてますが、分かる人には分かりますよね(笑)
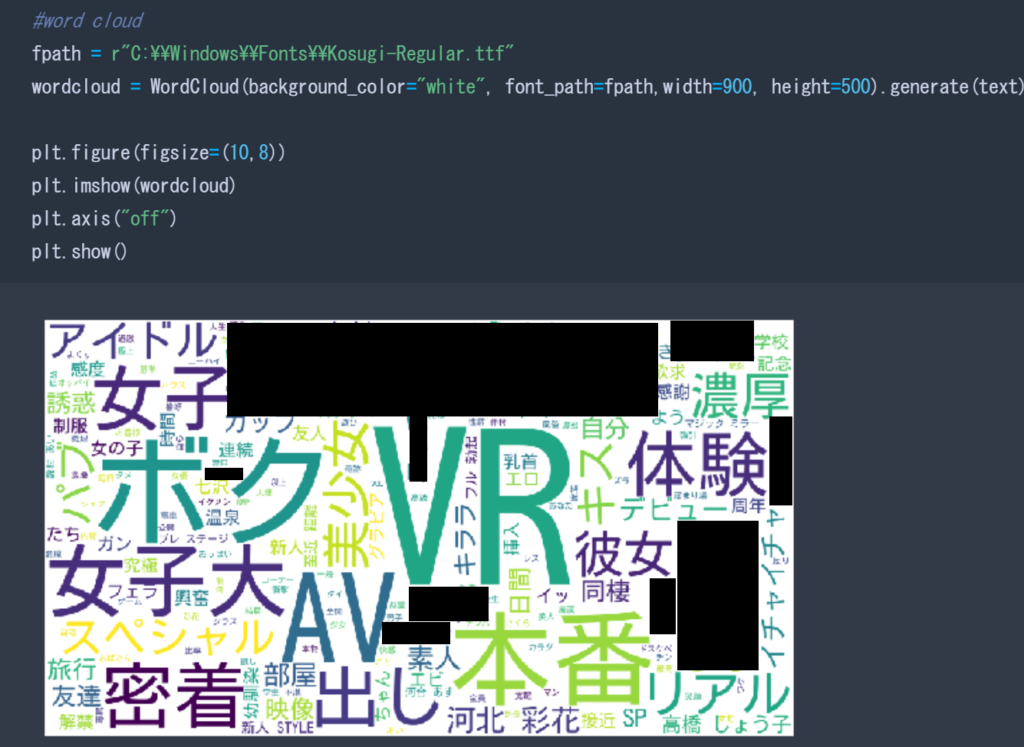
今回のコードでは2018年度の分析を主に行いました。
VR が最近の流行であると耳に挟んでいましたが、どうやら事実のようです。
ただ「ボク」も結構使用される頻度としては高いようです。
「ボク」の使われ方として考えられるのは2通りあります。
- 女優が「ボクっ子」である場合
- 出演者の一人称が「ボク」である場合
実際に2つ目のコード実行結果の中身を見てみると、後者の「出演者の一人称がボクである場合である」と確認できました。
問題は「何故売れているAVタイトルに『ボク』の使用回数が多いのか?」です。
この分析をしてみます。
人はコンテンツの主役になりたい

純粋にAV業界が VR の製品をプッシュして売っているだけの可能性もありますが、 「 VR 」の使用具合を見てみると、人気商品のほとんどが VR であることが確認できます。
VR は『目の前にいる』と錯覚するほどの体験が得られますよね。
例えば、ユニバーサルスタジオジャパンのハリーポッターの乗り物もそうです。
コンテンツとして VR は非常に強力なんだな、と思う一方、気になる点があるのです。
「 VR は派手だから売れるのではなく、体験型コンテンツと一目で分かるから売れるのではないだろうか?」

実際、「ボク」が使用されているのは、60位~80位の商品です。
そのため「ボク」を入れれば爆売れするわけではありませんが、「ボク」の使われ方は、出演者(男優)のことを指しています。
これは仮説ですが、「 AV を見る視聴者が、出演者と自分に親近感を持てるかどうか」もっといえば「自分はこのコンテンツの主役である」と錯覚できるかどうかが、売れるキーなのではないでしょうか。
まぁパッケージのお姉さんがタイプだったから、購入したという人がほとんどかもしれませんが。
終わりに
今回は Python でコーディング、実行したものを分析するところまでやってみました。
内容的にはバラエティー要素の強いものを採用しましたが、簡単に分析できるっていいですよね。